Making fast buffered logging.
For those of you who don't know, I've been working on a game engine completely from scratch in my (very limited) spare time. The name is NeonWood
Oddly enough I think this is the first actual post I've ever made about something I've made in zig... interesting.
I was debugging my multithreaded job dispatch system in my game engine and It seems to be doing fine, dispatching jobs to decode some 8k textures from highly compressed PNGs.
Now I'm not the brightest tool in the shed when it comes to multithreading but something seems really off here. This is the time it takes to dispatch a job.
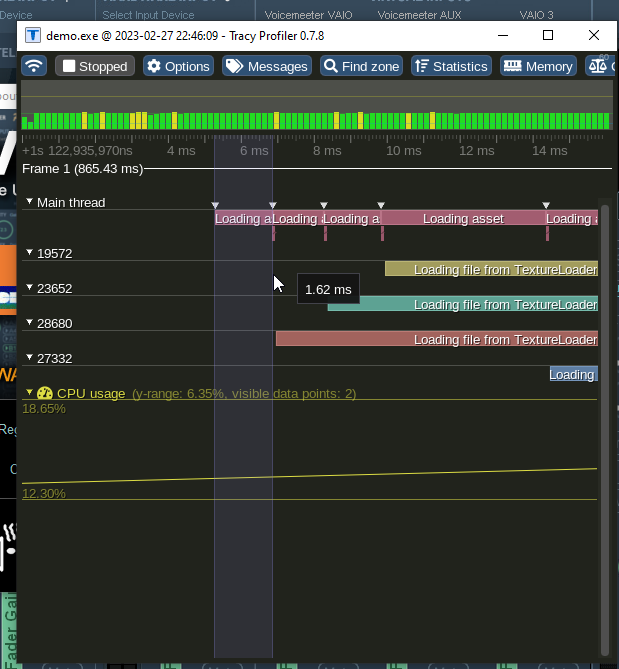
I dunno about you guys but.. 1.75 ms to dispatch a task is kind of unnacceptable.
Why was it even this bad? lets see what the code is doing.
var z = tracy.ZoneN(@src(), "AssetReferenceSys LoadRef");
core.engine_log("loading asset {s} ({s}) [{s}]", .{ asset.name.utf8, asset.assetType.utf8, asset.path });
try self.loaders.LoadAssetByType(asset.assetType, asset);
z.End();Uh.. ok? it seems like all it's doing is just creating a tracy zone then calling the loading function?
I bet it's the engine_log. It's printing directly to stdout under the hood.
Sigh.. lets comment that out.
Now with the debug prints removed we get some much more reasonable dispatch times.
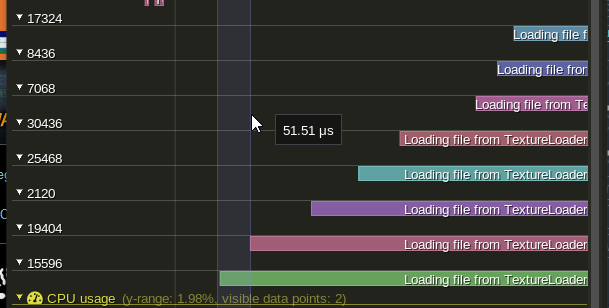
Honestly I kind of hate this. I don't nessecarilly want to have to lose the convenience of logging.
But while working on the engine's internals I want to have a finger on the pulse when it comes to performance.
What to do..
Well, about a day later and I massively reduced the time it takes to both dispatch the job as well as massively improved performance of debug prints in the engine as well.
here it is loading the previous previous test
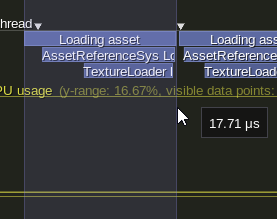
Here it is running the entire test, and the time it takes for the first loader function to start executing on the worker thread.
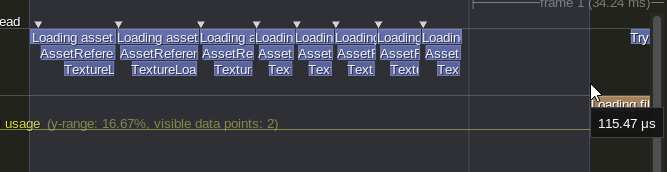
The technique I'm using is to write to an in memory buffer first. All
my _log functions now kick the print request to a logger
system. This has a fallback to debug print if for some reason the logger
print fails, or if it hasn't been initialized yet.
fn printInner(comptime fmt: []const u8, args: anytype) void {
if (gLoggerSys) |loggerSys| {
loggerSys.print(fmt, args) catch std.debug.print("!> " ++ fmt, args);
} else {
std.debug.print("> " ++ fmt, args);
}
}This logger system will flush out pending writes in it's write buffer periodically. It also has an internal buffer size of about 16k characters.
.writeOutBuffer = try std.ArrayList(u8).initCapacity(allocator, 8192 * 2),when a write causes the buffered character count to go above about half of the buffer size it forces a flush right a way. In this situation the forced flush will cause a stall in the 1 ms range.
if (self.writeOutBuffer.items.len > 8192) {
try self.flush();
}There's some stuff I can address with that later though.
The logger is of course also thread safe as it is guarded by a single mutex.
Fixing the stall.
That stall though from flush() is still horrendously bad
to me but at least we're not paying the cost of it in the hot path
anymore.
However look at this situation
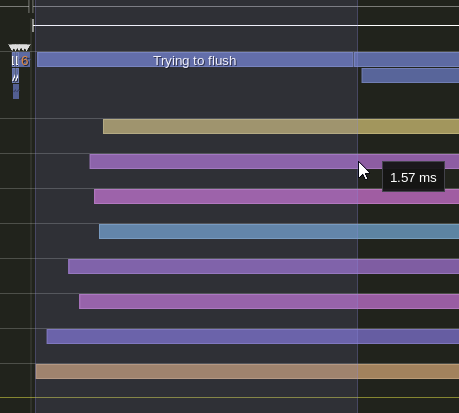
This is really bad. We can get rid of this by double buffering. This kicks out the expensive flush operation to a worker thread. via a swap operation.
var swap = self.writeOutBuffer;
self.writeOutBuffer = self.flushBuffer;
self.flushBuffer = swap;
const L = struct {
loggerSys: *LoggerSys,
pub fn func(ctx: @This(), _: *core.JobContext) void {
var z1 = tracy.ZoneN(@src(), "flushing output buffer");
defer z1.End();
ctx.loggerSys.flushFromJob() catch unreachable;
}
};
try core.dispatchJob(L{ .loggerSys = self });And of course all of this is done with zero allocations in the hot path.
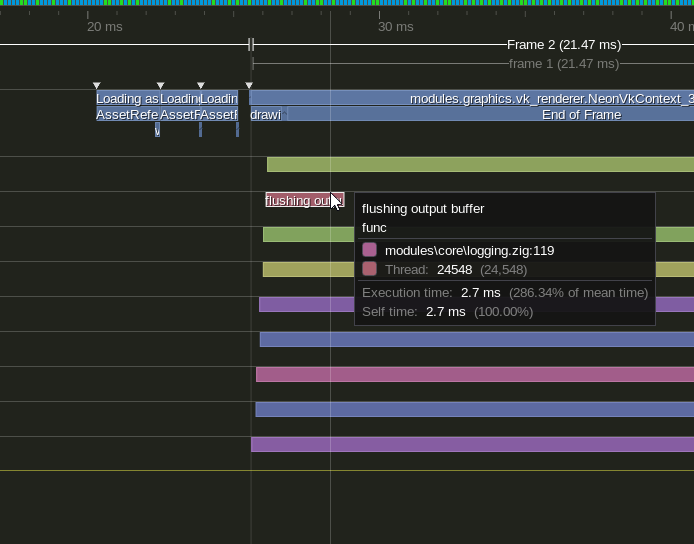
But what about overflow?
Well this is a case where stalls must be handled immediately.
if (self.writeOutBuffer.items.len > 8192) {
if (flushBufferLen == 0) {
try self.flush();
} else {
try self.flushWriteBuffer();
}
}Basically I add a seperate synchronous flush function that immediately flushes out whatever is currently in the write buffer. This emergency synchronous flush is only used if
- we are above our write buffer size for a single message, AND
- the flush buffer is still flushing.
I think those are acceptable situations for a stall.
There is just one mild issue left:
When the program crashes, anything still left in the buffer will not get dumped out. But there's lots of juicy details to talk about there, and will probably be a post for another time.